UrbanQ 공간데이터분석시스템(QGis Plugin)
UrbanQ 공간데이터분석시스템은 QGIS 벡터 데이터를 대상으로 데이터 품질 점검, 전처리, 지오메트리 검증, 주소·좌표 변환, 거리 분석 등 60여 종 이상의 기능을 코딩 없이 클릭만으로 자동화하는 통합 GIS 분석 플러그인입니다. 대용량 공간 데이터를 빠르고 정확하게 처리해 실무·연구·행정 업무의 생산성을 높입니다.
기능 개요
① Null/빈 값 통계 : 각 필드의 Null 값과 빈 문자열 수를 합산해 전체 대비 결측률(%)을 계산합니다.
예: 이름 필드에 Null과 빈 값이 30%이면, 70%만 값이 입력된 상태입니다.
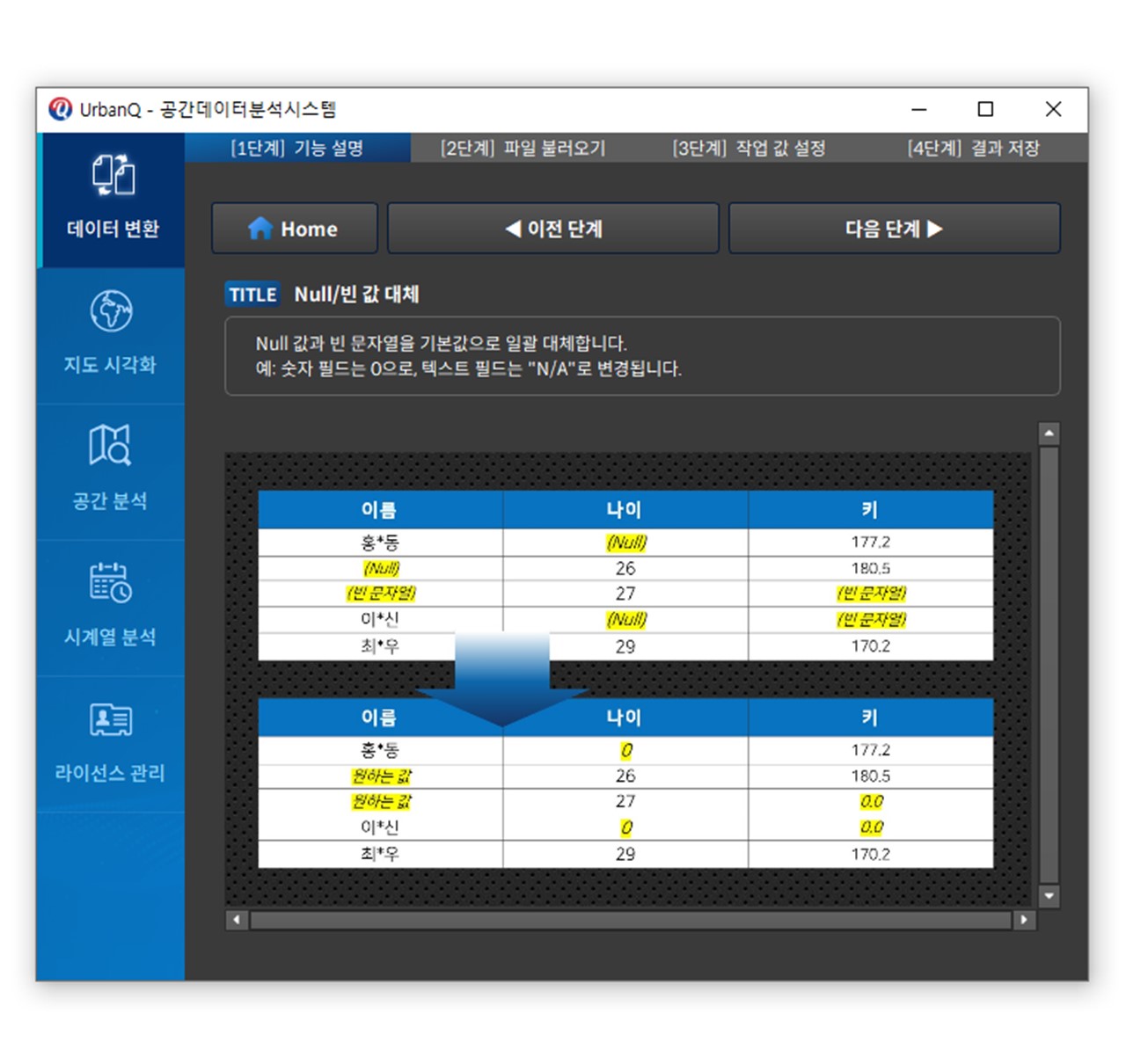
② Null/빈 값 대체 : Null 값과 빈 문자열을 기본값으로 일괄 대체합니다.
예: 숫자 필드는 0으로, 텍스트 필드는 “”N/A””로 변경됩니다.
③ Null/빈 값 레코드 삭제 : Null 값이나 빈 문자열이 포함된 행을 삭제합니다.
예: 주소 필드에 값이 없으면 해당 행이 삭제됩니다.
④ Null/빈 값 객체 지도에 표시 : Null 값이나 빈 문자열이 포함된 객체를 검출해 지도에서 자동으로 선택합니다.
예: 주소 필드가 비어 있는 객체는 QGIS에서 선택된 상태로 강조됩니다.
⑤ 필드 중복 값 통계 : 선택한 필드에서 중복된 값을 감지해 개수와 함께 표시합니다.
예: 이름 필드에서 ‘홍길동’이 3번 등장하면, 해당 중복 항목과 횟수를 보여줍니다.
⑥ 필드 중복 값 삭제 (1건만 유지) : 선택한 필드에서 중복된 값을 찾아, 하나를 제외한 나머지 중복 행을 삭제합니다.
예: 이름 필드에 ‘홍길동’이 3건 있을 경우, 1건만 남기고 나머지 2건을 삭제합니다.
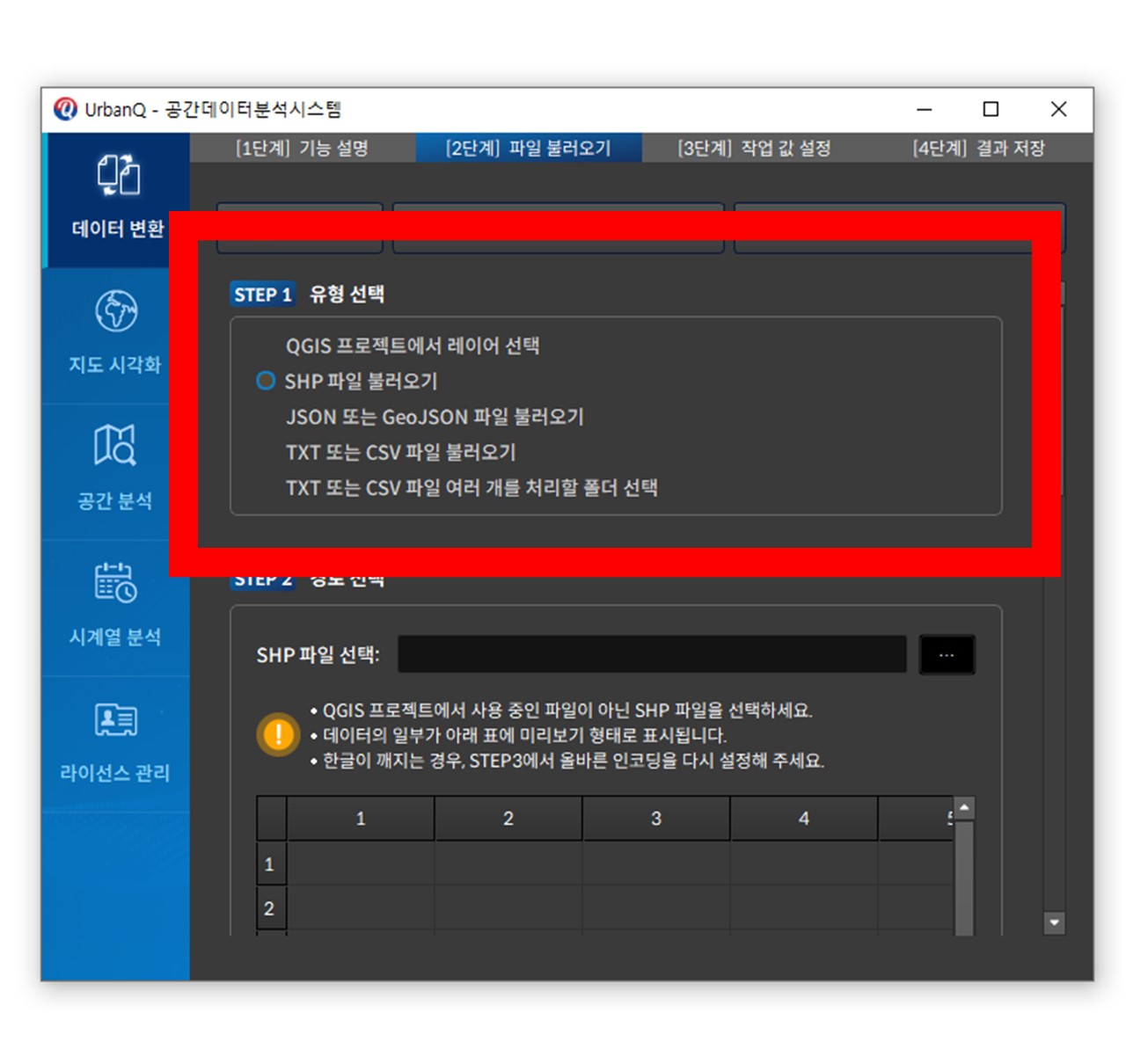
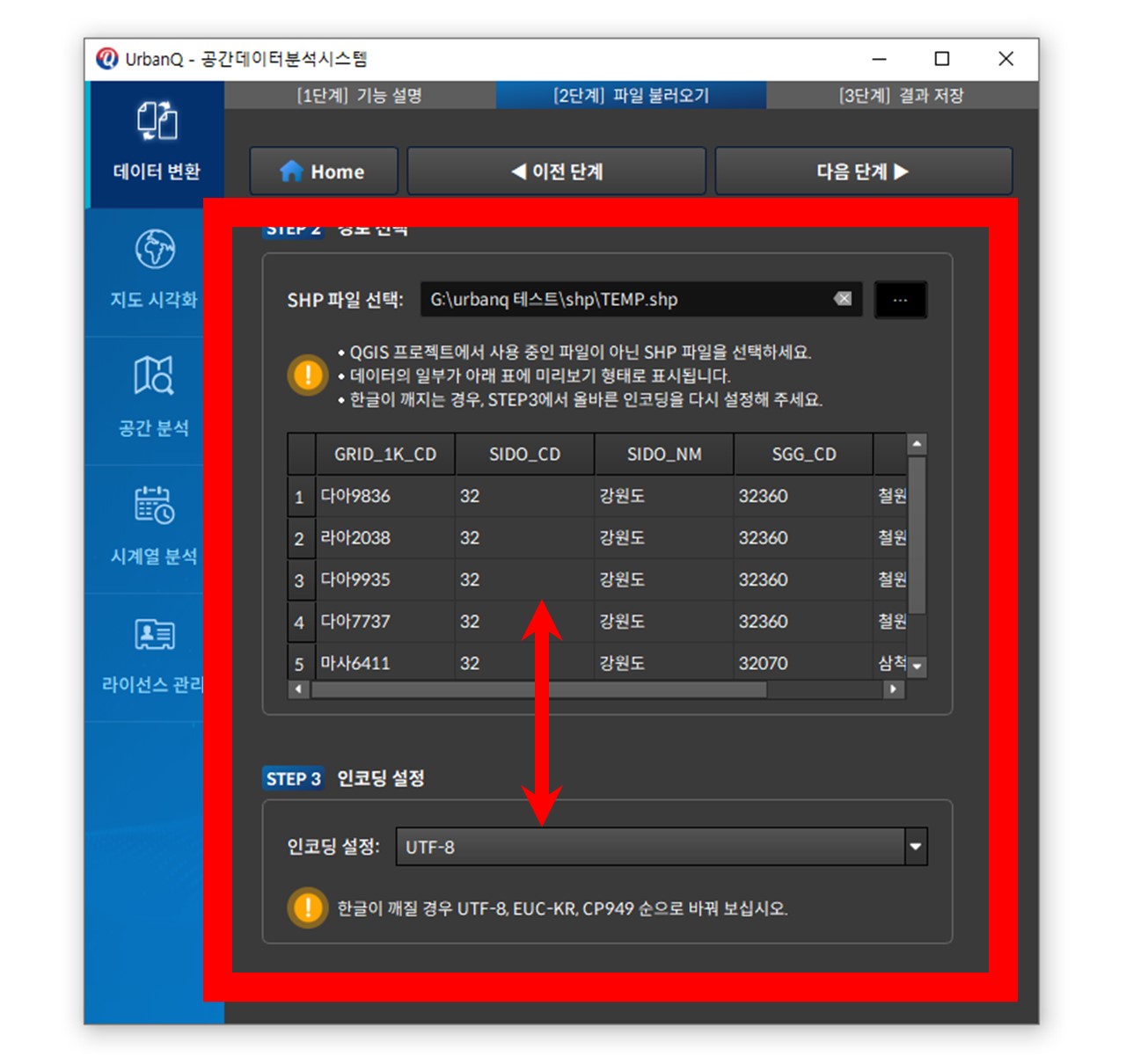
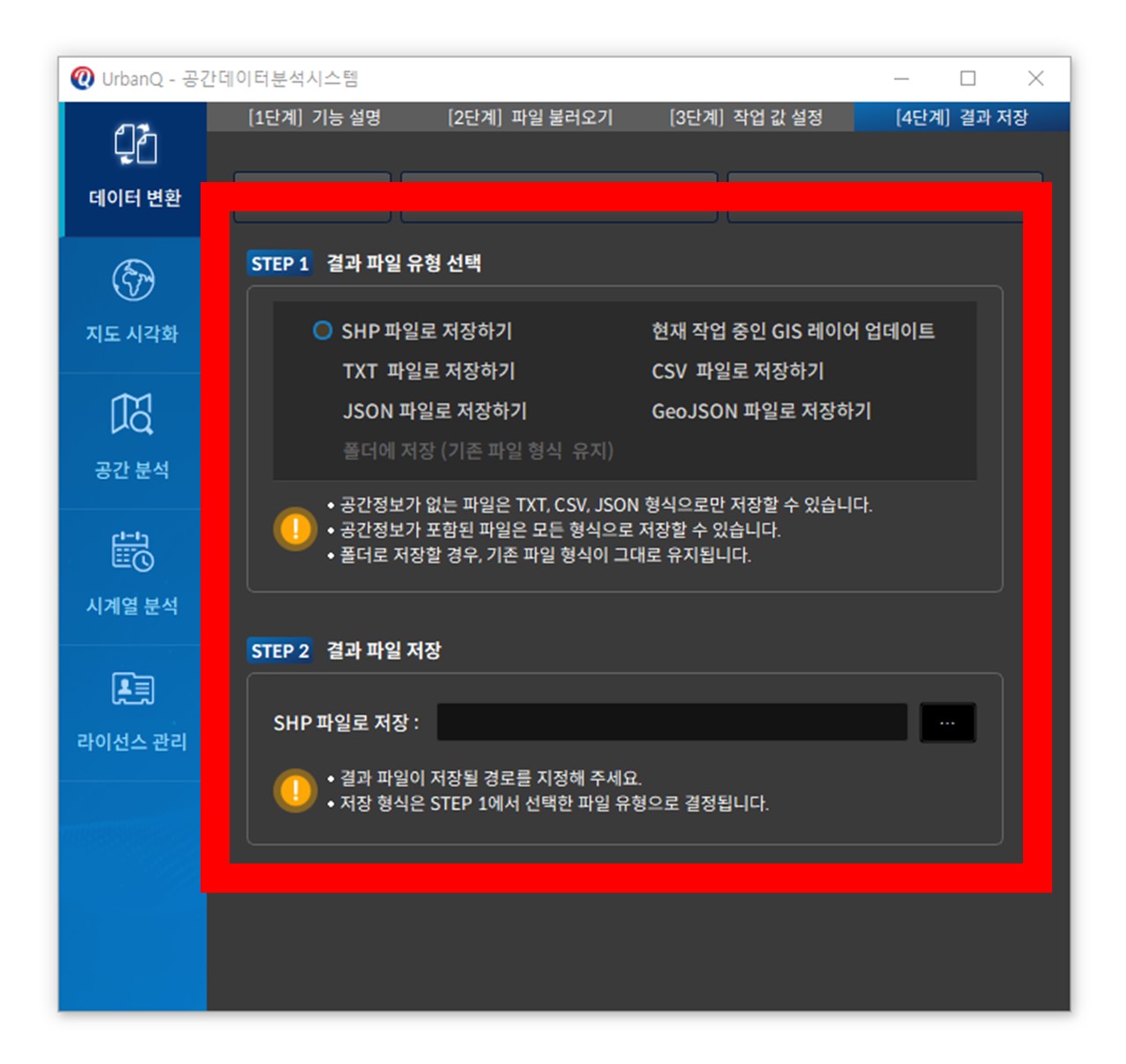
① 다양한 파일 형식 간 변환 : QGIS 레이어와 SHP, JSON, GeoJSON, TXT, CSV 형식의 공간 및 비공간 데이터를 서로 변환합니다.
예: SHP 파일을 GeoJSON으로 저장하거나, CSV 파일을 QGIS 레이어로 불러올 수 있습니다.
② 파일의 앞부분 N개 레코드 추출 : 대용량 파일에서 지정한 수(N)만큼의 상위 레코드를 추출해 빠르게 내용을 확인할 수 있습니다.
예: 총 10,000개 행 중 앞부분 100개 레코드만 미리보기로 표시합니다.
③ 필드 값의 상위 N개 레코드 추출 : 선택한 필드의 값을 기준으로 정렬하여, 상위 N개의 레코드만 추출합니다.
예: 인구수 필드에서 상위 5개 도시만 추출할 수 있습니다.
④ 필드 값의 하위 N개 레코드 추출 : 선택한 필드의 값을 기준으로 정렬하여, 하위 N개의 레코드만 추출합니다.
예: 인구수 필드에서 하위 5개 도시만 추출할 수 있습니다.
⑤ 특정 문자 또는 키워드 포함 레코드 추출 : 선택한 필드에서 입력한 문자, 키워드, 또는 패턴이 포함된 레코드만 필터링하여 추출합니다.
예: 주소 필드에서 ‘서울’이 포함된 레코드만 추출하거나, 이름에 ‘김’이 들어간 데이터만 확인합니다.
⑥ 지정한 행 구간으로 파일 짜르기 : 지정한 시작 행(n)부터 끝 행(n+m)까지의 데이터만 선택하여 파일로 저장합니다.
⑦ 지정한 행 개수로 n개 파일 나누기 : 지정한 행 개수(n)를 기준으로 데이터를 여러 개의 파일로 나누어 저장합니다.
① 필드 통계 (개수·평균·합계 등) : 하나의 숫자 필드를 대상으로 전체 레코드에 대해 개수(count), 평균(mean), 합계(sum), 최대값(max), 최소값(min) 등을 표 형태로 제공합니다.
예: ‘인구수’ 필드 전체에 대해 평균, 합계, 최대값, 최소값, 개수 등의 통계를 표로 표시합니다.
② 필드 그룹화 통계(개수·평균·합계 등) : 하나의 필드를 기준으로 레코드를 그룹화한 뒤, 다른 숫자 필드에 대해 각 그룹별 개수(count), 평균(mean), 합계(sum), 최대값(max), 최소값(min) 등의 통계 정보를 표 형태로 제공합니다.
예: ‘행정동’ 기준으로 그룹화 → 각 행정동별 ‘인구수’ 평균(mean)과 합계(sum) 계산
③ 필드 랭킹(순위) 계산 : 선택한 필드 값을 기준으로 레코드를 내림차순 정렬하여 순위를 계산하고, 해당 순위를 새로운 필드로 저장합니다.
예: ‘인구수’ 기준 → 가장 인구가 많은 지역부터 순위 부여 → ‘순위’ 필드에 저장
④ 두 필드 간 비율 계산 : 두 개의 필드 값을 활용하여 비율을 A/B 방식으로 계산하고, 결과를 새로운 필드로 저장합니다.
예: ‘여성 인구’ / ‘전체 인구’ → 여성 비율(%)을 새 필드에 저장
⑤ 필드 특정 구간 레코드 추출 : 선택한 필드에서 사용자가 지정한 값의 범위(최소값~최대값)에 해당하는 레코드만 추출합니다.
예: ‘온도’ 필드에서 20도 이상, 30도 이하의 레코드만 추출
⑥ 필드 값 정규화 (0~1 범위로 변환) : 선택한 숫자형 필드를 0~1 범위로 정규화하여 값의 크기를 상대적으로 비교할 수 있도록 변환합니다.
예: ‘인구수’ 필드의 최소값 10, 최대값 100일 경우 → 인구수 10은 0.0, 100은 1.0, 50은 0.5로 변경됩니다.
⑦ 필드 값 고정 범위 재조정 : 선택한 숫자형 필드의 값을 사용자가 지정한 최소~최대 범위 내로 강제로 조정합니다.
예: 0~100 범위로 설정한 경우 → 120은 100으로, -20은 0으로 조정됩니다.
① 앞뒤 공백 삭제 : 필드 값에 포함된 앞쪽 또는 뒤쪽 공백(스페이스, 탭 등)을 제거합니다.
예: ‘ 서울 ‘ → ‘서울’
② 특정 문자 또는 부호 삭제·치환 : 선택한 필드에서 특정 문자 예를 들어 쉼표, 괄호, 따옴표 등 불필요한 특수 문자를 삭제합니다.
예: ‘서울-강남구’ → ‘서울강남구’ 또는 ‘인천-서구’ → ‘대전-서구’
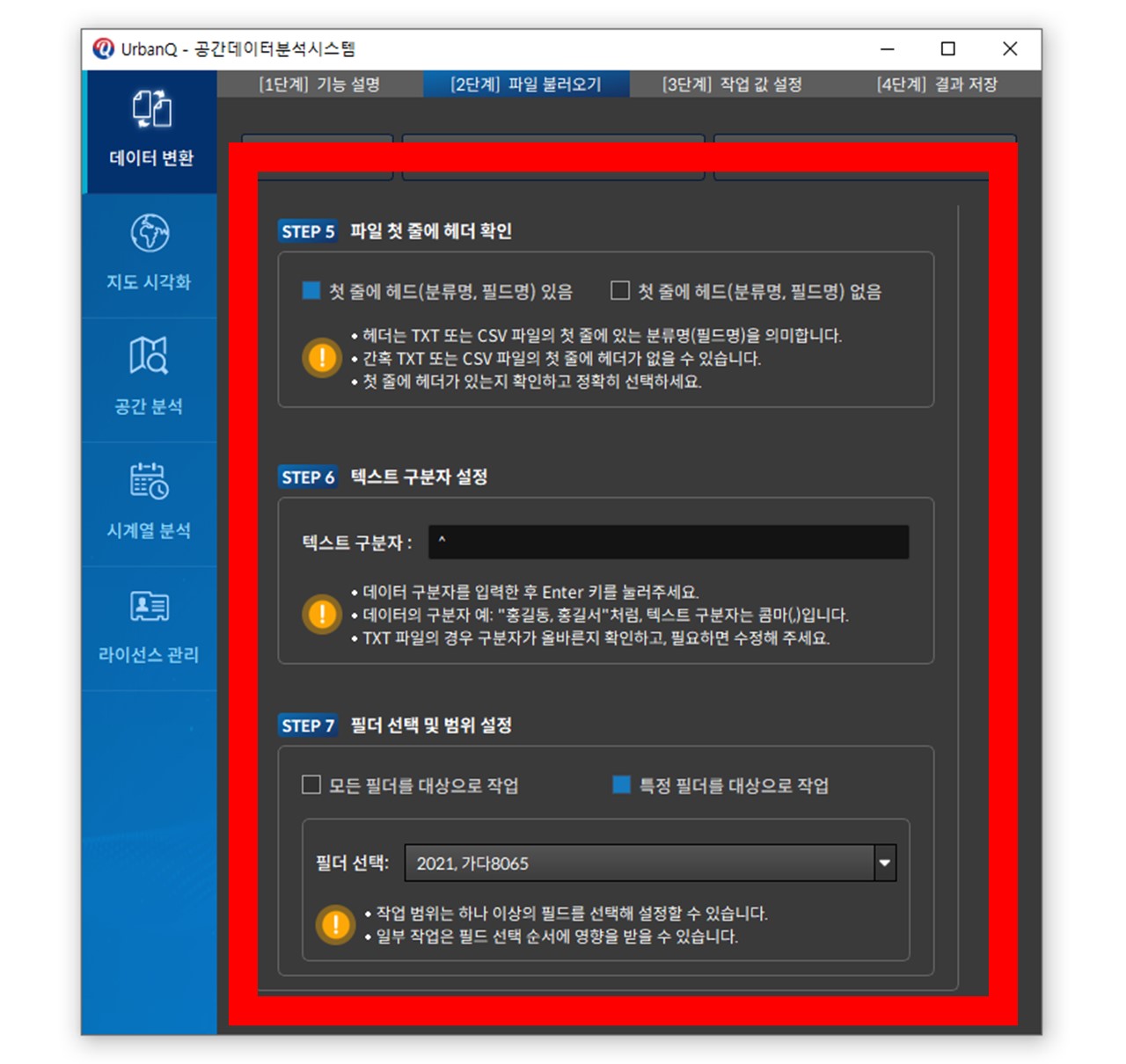
③ 구분자 기준 텍스트 분리 : 쉼표(,), 슬래시(/), 하이픈(-) 등 특정 구분자를 기준으로 문자열을 나누고 새 필드에 저장합니다.
예: ‘서울특별시, 강남구’ → ‘서울특별시’, ‘강남구’로 분리하여 두 개의 필드에 저장
④ 대소문자 변환 : 문자열을 모두 대문자, 모두 소문자, 첫 글자만 대문자로 변환하여 세 개의 필드에 저장합니다.
예: ‘seoul’ → ‘SEOUL’, ‘seoul’, ‘Seoul’
⑤ 구분자 사이 문자열 추출 : 앞쪽 구분자와 뒤쪽 구분자 사이에 위치한 문자열을 추출합니다. 앞쪽 구분자가 없으면 문자열의 처음부터, 뒤쪽 구분자가 없으면 문자열의 끝까지 포함하여 추출합니다.
예: ‘서울/강남구/논현동’ → ‘강남구’ (앞 구분자: ‘/’, 뒤 구분자: ‘/’)
⑥ 필드 값 범위 추출 : 필드 값에서 지정한 시작 번호부터 끝 번호까지의 텍스트만 추출하여 저장합니다.
예를 들어, abcdefg에서 2~5번을 지정하면 **bcde**가 추출됩니다.
① 공통 필드 기준 레이어 병합(초고속) : 여러 파일(SHP, CSV 등)을 공통 필드(예: ID)로 병합해 하나의 통합 레이어로 만듭니다.
예: ‘행정코드’를 기준으로 SHP와 인구 통계 CSV를 병합해 하나의 레코드로 만듭니다.
② 속성 값 동기화(초고속) : 외부 파일(CSV 등)을 기준으로 기존 레이어의 속성값을 비교해, 변경된 항목만 자동으로 업데이트합니다.
예: 건물 층수나 이름이 변경된 경우, 기존 SHP에 최신 값을 반영합니다.
③ 열 개수 같은 n개 파일 수직 병합(초고속) : 폴더 내 모든 txt/csv 파일을 대상으로, 필드명을 무시하고 열 개수 일치할 경우, 빠르게 수직 병합합니다.
예: 열 개수가 같은 2024_01.csv와 2024_02.csv를 아래로 이어붙여 하나의 파일로 병합합니다.
④ 행 개수 같은 n개 파일 수평 병합(초고속) : 폴더 내 모든 txt/csv 파일을 대상으로, 필드명을 무시하고 행 개수 일치할 경우, 빠르게 수평 병합합니다.
예: 행 개수가 같은 두 파일의 속성을 옆으로 이어붙여 하나의 레이어로 만듭니다.
① 필드 값 빈도 계산 : 각 속성 값의 출현 빈도를 계산하여 통계합니다.
예: 동일한 지역명이 몇 번 등장하는지 기록합니다.
② 필드 값 일괄 수정 : 여러 개의 필드를 일괄 선택하면 필드의 유형를 자동 감지하고 특정 값으로 초기화합니다.
예: 선택한 필드의 값을 일괄 0으로 수정합니다.
③ 특정 부호로 여러 필드 결합 : 선택한 여러 필드의 값을 특정 구분자(예: ‘-’, ‘/’, ‘,’ 등)로 연결하여 하나의 필드로 결합합니다.
예: 시·군·구·도로명을 결합하여 전체 주소를 구성합니다.
④ 날짜 필드 년, 월, 일로 분리 : 날짜 형식 필드를 자동 인식하여 연도(Year), 월(Month), 일(Day)로 분리하여 각각의 필드로 생성합니다.
날짜 형식 예: 2024-05-25, 2024.05.25, 2024/05/25, 20240525, 24-05-25, 05/25/2024
① 고유 ID 필드 생성 : 각 레코드에 대해 0 또는 1부터 시작하는 고유 숫자를 순차적으로 부여하는 필드를 생성합니다.
예: 첫 번째 레코드부터 차례로 0, 1, 2와 같은 숫자가 입력됩니다.
② 무작위 N자리 숫자 생성 : 추가한 필드에 중복되지 않는 무작위 N자리 숫자를 생성하여 입력합니다.
예: 데이터 익명화나 샘플링을 위한 고유 식별자로 8493021, 2938174와 같은 숫자를 생성할 수 있습니다.
③ 새로운 문자열 필드 생성 : 새로운 문자열 필드를 추가하고, 기본값은 빈 문자열로 초기화됩니다.
예: 추가된 ‘이름’ 필드 값이 빈 값으로 설정됩니다.
④ 필드 이름 변경 : 기존 필드의 이름을 원하는 새 이름으로 바꿉니다.
예: ‘지역명’이라는 필드를 ‘행정구역’으로 변경할 수 있습니다.
⑤ 필드를 숫자 유형으로 변경 : 선택한 필드의 값을 숫자 형식으로 변환합니다. 먼저 정수(int) 형식으로 변환을 시도하고, 실패할 경우 실수(float) 형식으로 재시도합니다.
예: ‘123’(문자열)을 123(정수)로, ‘45.67’(문자열)을 45.67(실수)로 변환할 수 있습니다.
⑥ 필드 순서 변경 : 속성 테이블 내 필드(열)의 순서를 사용자가 지정한 순서대로 재배치합니다.
예: ‘A’, ‘B’, ‘C’ 순서를 ‘C’, ‘A’, ‘B’로 변경합니다.
⑦ 필드 복사 : 기존 필드를 그대로 복제하여 동일한 값을 가진 새로운 필드를 생성합니다.
예: ‘이름’ 필드의 값을 복사하여 ‘이름_복사’라는 새 필드에 동일한 값으로 추가합니다.
① 주소 불필요 정보 정제 : 주소 내 건물명, 괄호, 동·호수 등 불필요한 정보를 제거하여 표준 주소로 정제합니다.
예: 서울 강남구 테헤란로 152 (역삼동, 파이낸스센터 20층) → 서울 강남구 테헤란로 152
② 지번 → PNU 변환 : 지번주소를 부동산 행정 관리용 토지 고유번호(PNU)로 변환합니다.
예: 서울 강남구 역삼동 737-10 → 1168010100107370000
③ 지번 → 좌표 변환 (지오코딩) : 지번주소를 공간 좌표(경도·위도)로 변환하여 위치 정보를 생성합니다.
예: 서울 강남구 역삼동 737-10 → (127.0281, 37.4979)
④ 지번 → 도로명 변환 : 지번주소를 공식 도로명주소 체계로 자동 변환합니다.
예: 서울 강남구 역삼동 737-10 → 서울 강남구 테헤란로 152
⑤ 도로명 → 좌표 변환 (지오코딩) : 도로명주소를 경도·위도 좌표로 변환하여 공간 분석에 활용합니다.
예: 서울 강남구 테헤란로 152 → (127.0281, 37.4979)
⑥ 도로명 → 지번 변환 : 도로명주소를 지번주소 체계로 자동 역변환합니다.
예: 서울 강남구 테헤란로 152 → 서울 강남구 역삼동 737-10
① 대한민국 좌표 위치 자동 보정 : 좌표계 정보가 없거나 잘못된 레이어를 분석하여, 대한민국 위치에 맞도록 자동 보정합니다.
예: 좌표계 미지정 SHP·TXT 파일 → 대한민국 정확한 위치에 자동 배치
② 지오메트리 오류 객체 통계 : 객체의 지오메트리 유효성을 검사하여 오류를 자동으로 탐지해 전체 대비 결측률(%)을 계산합니다.
예: 객체 100개 중 5개가 오류일 경우, 오류율 5% 상태입니다.
③ 지오메트리 오류 객체 지도에 표시 : 지오메트리 오류가 있는 객체를 검출해 QGIS 지도에서 자동으로 선택합니다.
예: 닫히지 않거나 오류 폴리곤이 포함된 객체는 QGIS에서 선택된 상태로 표시됩니다.
④ 중복 지오메트리 탐지 및 제거 : 동일한 위치와 크기 및 형태의 중복 지오메트리 객체를 자동 탐지하여 하나만 유지합니다.
예: 동일한 건물 폴리곤 3개 → 1개만 유지
⑤ 중복 객체(지오메트리 + 필드) 탐지 및 제거 : 동일한 지오메트리(위치, 크기, 형태 모두 동일)이며 선택한 필드 값까지 모두 같은 중복 객체를 자동 제거합니다.
예: 동일한 건물 폴리곤과 필드값이 같은 3개 → 1개만 유지
⑥ 겹침(Overlap) 객체 검출 : 객체 간 중복 영역(겹침)을 자동 분석하여 문제가 되는 객체를 지도에서 표시합니다.
예: 두 필지 폴리곤이 서로 겹쳐 있는 경우 해당 두 객체를 자동 선택
⑦ 슬리버 폴리곤 검출 및 지도에 표시 : 면적이 비정상적으로 작은 슬리버(찌꺼기) 폴리곤을 자동 탐지하여 정리 대상 객체로 표시합니다.
예: 면적 0.1㎡ 미만의 불필요한 미세 폴리곤 검출
① 중심점 추출 : 폴리곤·라인 객체의 중심점을 계산하여 새로운 포인트 레이어로 생성 및 저장합니다.
예: 건물 폴리곤 → 중심점 포인트 레이어 생성 및 저장
② 객체 면적 자동 계산 : 모든 폴리곤 객체의 면적을 자동 계산하여 새로운 필드에 저장합니다.
예: 건물 폴리곤 → 면적(㎡) 필드 자동 생성
③ 객체 버퍼 생성 : 지정한 거리만큼 객체의 버퍼 영역을 자동 생성하여 새로운 레이어로 저장합니다.
예: 도로 중심선 → 50m 영향권 버퍼 생성
④ 폴리곤 지오메트리 단순화 : 폴리곤 객체의 형상을 단순화하여 데이터 용량을 줄이고 지도 성능을 향상시킵니다.
예: 복잡한 건물·행정경계 폴리곤을 저용량 형상으로 변환
⑤ 라인 지오메트리 단순화 : 라인 객체의 형상을 단순화하여 데이터 용량을 줄이고 지도 성능을 향상시킵니다.
예: 고해상도 도로·경계선을 저용량 선형 데이터로 변환
⑥ 지오메트리 스냅 정렬 : 인접 객체의 경계를 자동 정렬하여 미세한 오차를 제거합니다.
예: 필지 경계가 살짝 어긋난 경우 자동 정렬 및 수정합니다.
⑦ 폴리곤 홀(Hole) 제거 : 폴리곤 내부의 불필요한 홀(구멍)을 자동 제거하여 정상 객체로 보정합니다.
예: 내부에 빈 공간이 존재하는 폴리곤을 단일 면으로 복구
① 분석 대상→참조 대상 거리 계산 : 분석 대상 레이어의 각 객체에 대해 참조 레이어의 모든 객체까지의 거리를 계산합니다.
예: 집(2개) → 병원(4개) → 집 레이어에 dist_1~4 (병원1~4) 필드 생성 및 거리 저장
② 분석 대상→참조 대상 최근접 N개 거리·속성 : 분석 대상 레이어의 각 객체에 대해 참조 레이어에서 가장 가까운 N개 객체를 찾고, 각 객체까지의 거리와 지정한 속성값을 함께 저장합니다.
예: 집(2개) → 병원(4개 중 N=2) → 집 레이어에 min_dist_1~2, min_uid_1~2 필드 생성 및 저장
③ 분석 대상→참조 대상 반경 내 객체 수 : 분석 대상 레이어 기준 반경(R) 이내 참조 레이어 객체 수를 계산하여 저장합니다.
예: 집 → 500m 내 병원 수를 집 레이어의 count 필드에 저장
④ 동일 레이어 최근접 N개 거리·속성 : 동일 레이어 내 각 객체에 대해 가장 가까운 N개 이웃 객체의 거리와 지정한 속성값을 함께 저장합니다.
예: 병원 → 가장 가까운 2개 병원의 거리와 이름을 min_dist_1~2, min_uid_1~2 필드로 저장
⑤ 거리 구간 분류 : 계산된 거리 필드를 사용자가 지정한 구간별 등급으로 분류하여 저장합니다.
예: 0~100m=A, 100~200m=B, ……, 700m 이상=G 등과 같이 영문자 등급 부여
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}